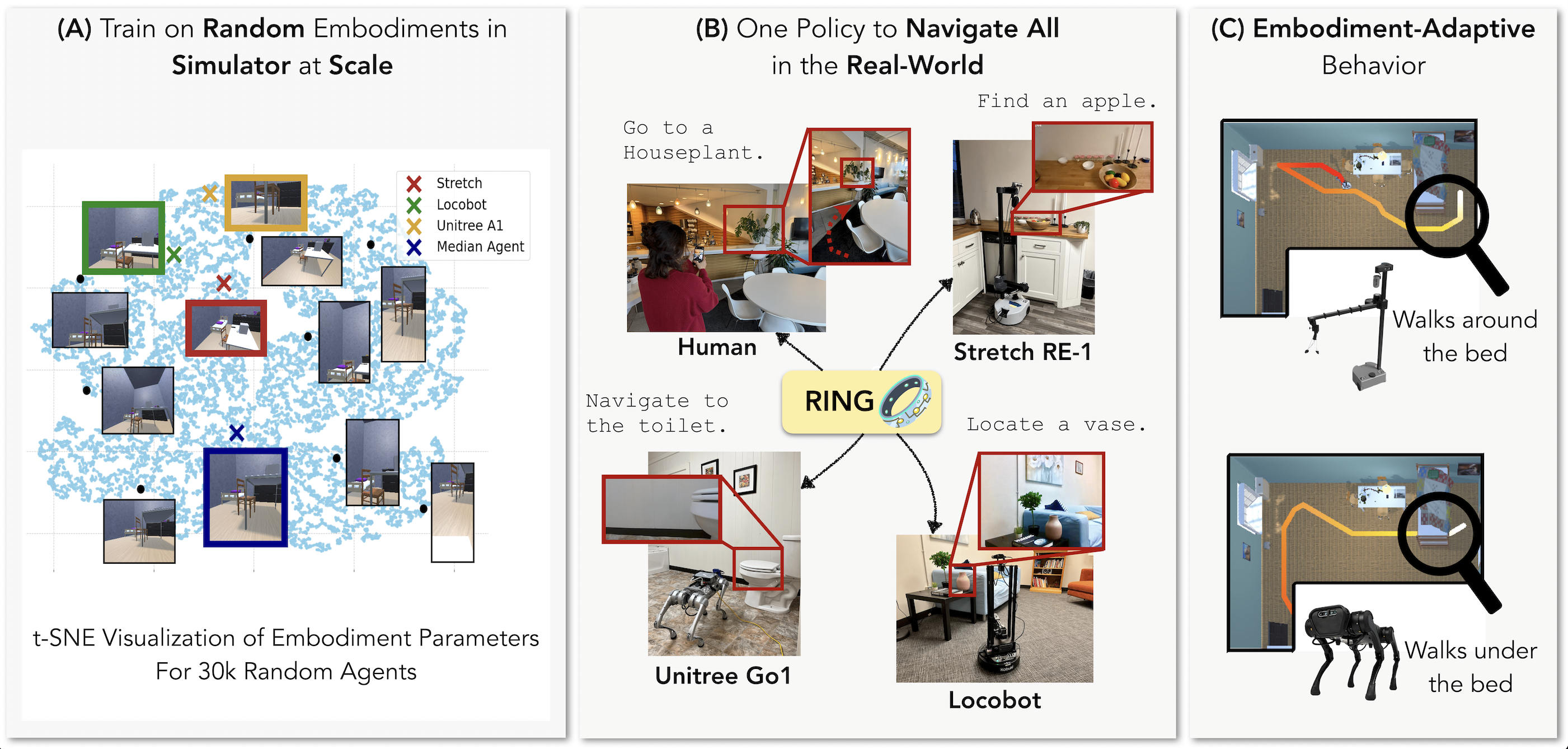
RING (Robotic Indoor Navigation Generalist) is an embodiment-agnostic policy, trained solely in simulation with diverse randomly initialized embodiments at scale (1 Million embodiments).
RING achieves robust performance on unseen robot platforms (RB-Y1, Stretch RE-1, LoCoBot, Unitree’s Go1) in the real world, despite being trained exclusively in simulation without any direct exposure to real robot embodiments (see Quantitative Results).
We use simulation to randomly sample 1 Million body configurations, varying the robot’s camera parameters, collider sizes, and center of rotation (see Embodiment Randomization at Scale).
Coverying the space of possible embodiments allows RING to zero-shot generalize to unseen real-world robots with different body sizes and camera placements (see Real-World Qualitative Results).
RING also shows embodiment-adaptive behavior, adapting its navigation strategy based on the embodiment (see Embodiment-Adaptive Behavior).
Website contents
This website contains a collection of qualitative examples and quantitative results of our RING policy in the
real-world and simulation. We also provide details about our data, training recipe, and model architecture.
We evaluate RING directly on 5 unseen robots--RB-Y1 (wheeled humanoid), Stretch-RE1, Stretch-RE1(factory config), LoCoBot, Unitree Go1--without any further adaptation or real-world-specific finetuning.
Here we present a trajectory for each robot embodiment. The agent's RGB input as
well as a 3rd person perspective is shown for each example. All videos are sped up by up to 20x for ease
of viewing.
[We use black boxes to hide individuals' identities when they appear in the frame.]
RB-Y1 (wheeled humanoid):
We deploy RING on the RB-Y1 wheeled humanoid in an unstructured real-world kitchen area, where it successfully navigates to different target objects (trashcan, apple, houseplant, mug) at two different heights (standing/seated).
We use an iPhone 16 Pro camera mounted on the robot to stream visual observations.
To demonstrate RING's robustness to viewpoint changes, we randomly alter the robot's height mid-trajectory for the apple target.
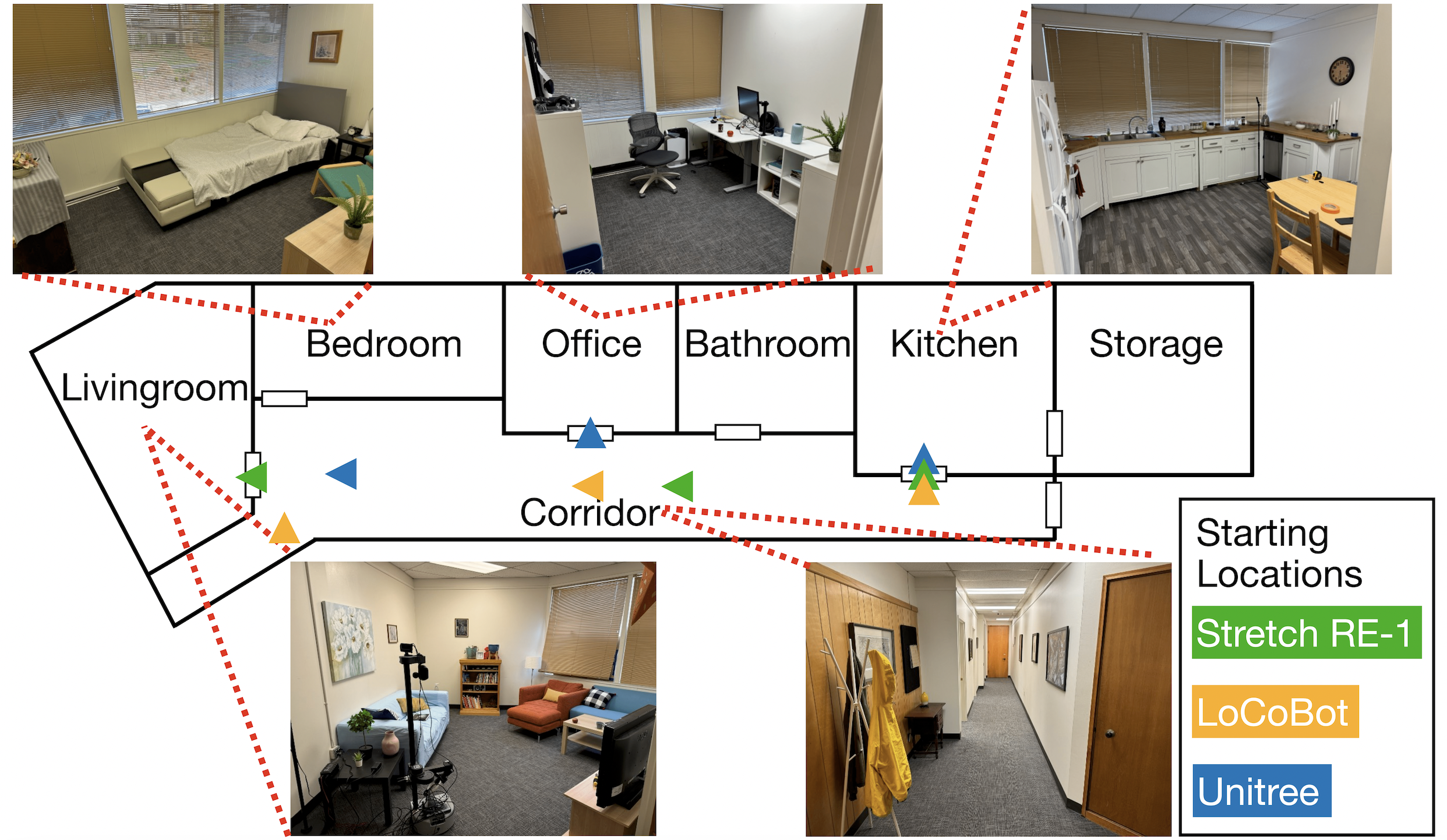
Four other embodiments (Stretch-RE1, Stretch-RE1 (factory config), LoCoBot, Unitree Go1):
We evaluate other robot platforms in a multi-room real-world apartment with layout shown below.
Floorplan of the real-world apartment.
Stretch RE-1 (factory config camera): Find an apple.
In this experiment, we use the original off-the-shelf camera equipped on the Stretch RE-1 (D435 with a vertical field of view of $69^{\circ}$ and resolution of $720 \times 1280$).
RING effectively explores the room and finds the apple despite having a narrow field of view.
Stretch RE-1 (camera config used in SPOC): Find a mug.
For this embodiment, following SPOC, we use 2 Intel RealSense 455 fixed cameras, with a vertical field of view of $59^{\circ}$ and resolution of $1280 \times 720$.
RING explores multiple rooms while avoiding obstacles to find the mug.
Unitree Go1: Move to the toilet.
We use Unitree Go1 as another embodiment with lower height.
The robot navigates to the toilet from the living room.
Please note that our low-level controller is not perfect, causing the robot to drift to left when moving forward.
Despite this limitation, RING shows robustness by correcting the robot's trajectory using RotateRight actions.
LoCoBot: Find a basketball.
The robot starts in a bedroom with 3 full 360 degree rotations to scan the room.
It then navigates to the corridor and finds the basketball.
The exhaustive exploration of the bedroom is due to the bias in simulation where the basketball is often placed in the bedroom.
Embodiment-Adaptive Behavior.
Stretch RE-1 & Unitree Go1: Navigate to the trashcan.
Both robots go to the kitchen to find the trashcan.
In the left video, Stretch goes around the table in the corridor to avoid collisions.
In the right video, when the table completely blocks the way, RING controls the Go1 robot to walk under the table because of its lower height.
Failure due to embodiment limitation.
Unitree Go1: Go to the sofa (Failed).
This example shows a failure example due to an embodiment limitation.
The Go1 robot has a low camera placement with a limited field of view.
This results in incorrectly identifying a leather bench at the foot of the bed as a sofa.
(Please refer to the robot's first-person view to observe the recognition error.)
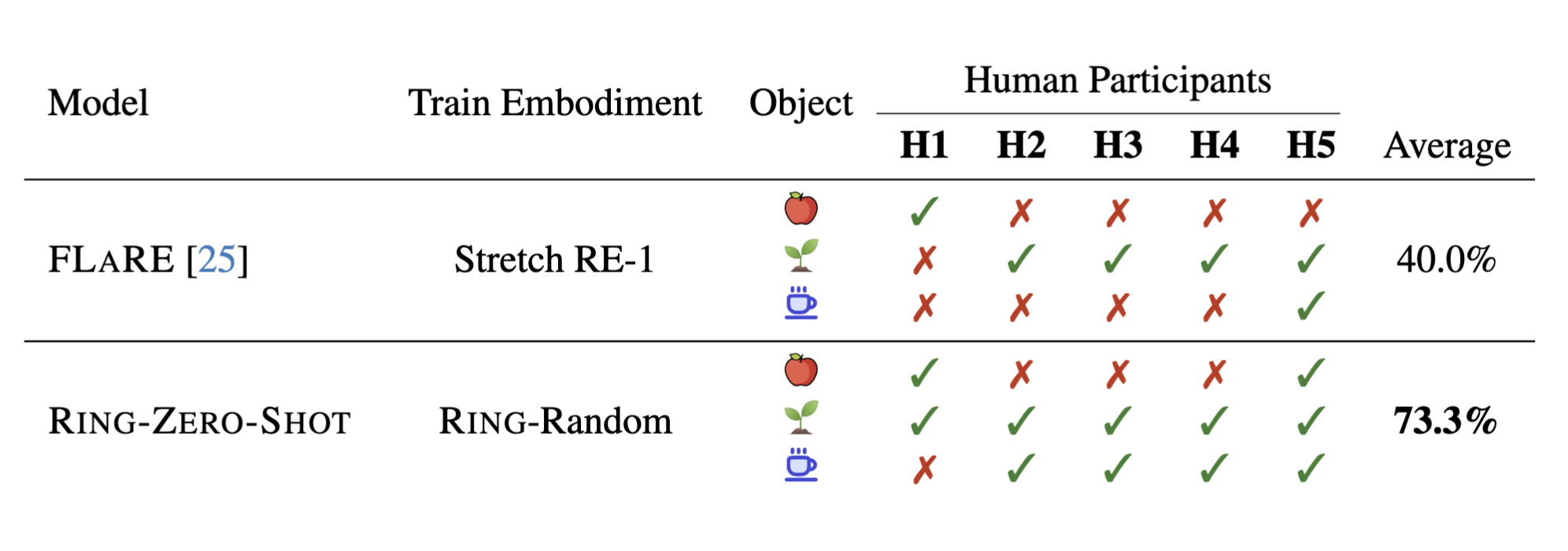
Human Evaluation
To further show RING's generalization capability to novel embodiments, we evaluate it as a navigation assistant with humans as new, unseen embodiments.
We asked 5 participants to navigate in a real-world kitchen area, following the policy’s output actions on their phones.
Each individual has unique characteristics, including step size, height, rotation angles, and camera-holding posture. Each person navigates to three different objects (Mug, Apple, Houseplant), resulting in a total of 15 trajectories.
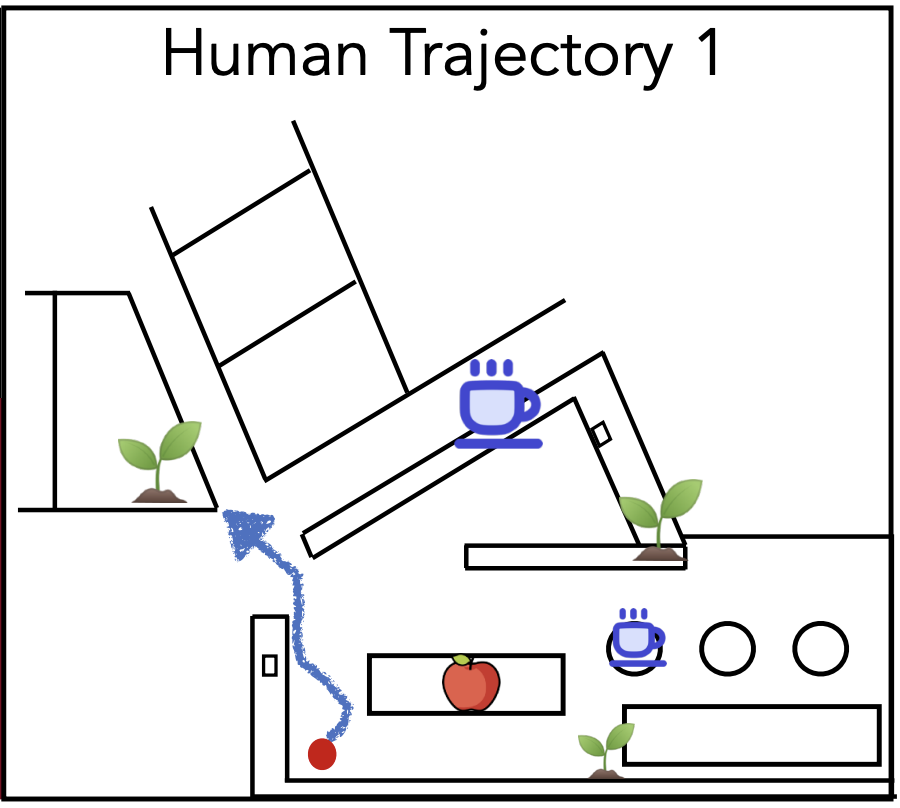
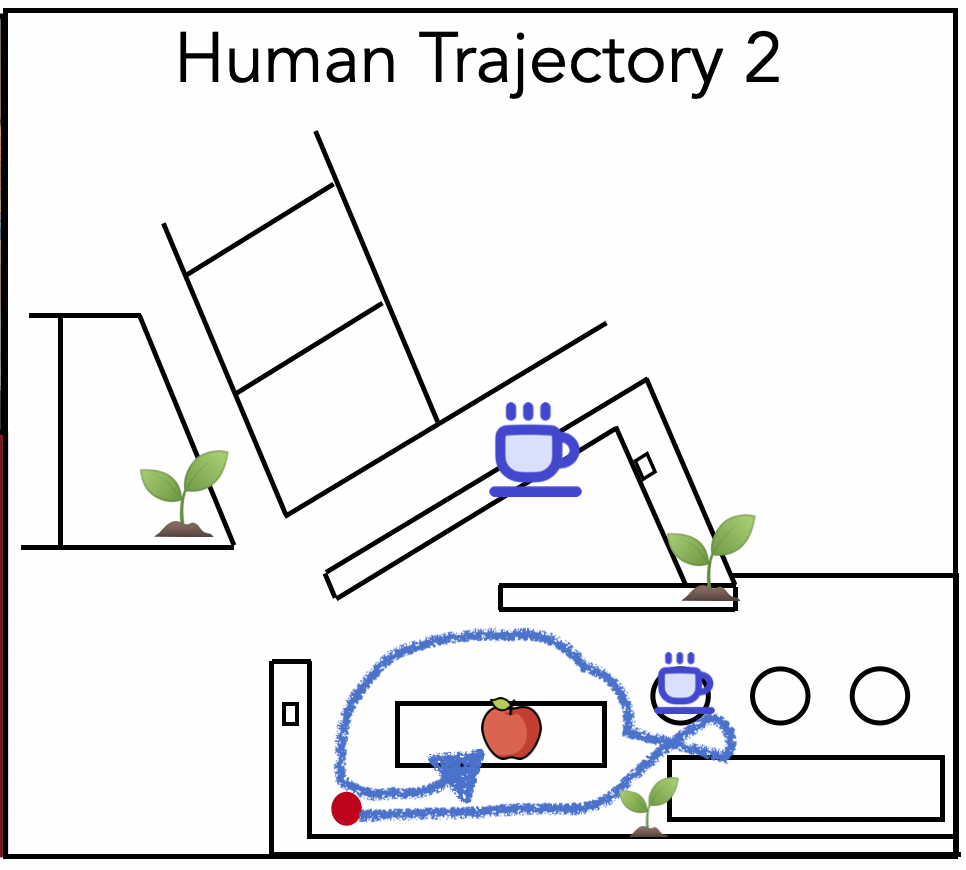
Below we show two qualitative trajectories navigated by two participants using RING.
Find a houseplant.
Find an apple.
RING has Embodiment-Adaptive Behavior
The RING policy shows embodiment-adaptive behavior.
In the simulation, both Stretch RE-1 and Unitree A1 start from the same pose behind the bed. The quadruped robot directly moves under the bed because of its lower height, while the Stretch RE-1 bypasses it.
Then, our third agent matches the Stretch RE-1’s height but has a camera positioned as low as the quadruped’s. Initially, it assumes a lower height and attempts to go under the bed, but after colliding, it adjusts to maneuver around the bed, similar to the Stretch RE-1.
This shows RING implicitly infers embodiment parameters from visual observations and transition dynamics, dynamically adjusting its navigation strategy accordingly.
It does not have access to any privileged information about its current body. This embodiment-adaptive navigation strategy adjustment is an interesting emergent behavior that would not have been possible without training across the exhaustive space of embodiments at scale.
RING (Robotic Indoor Navigation Generalist)
With the growing diversity of robots used in real-world applications, there remains a need for a policy that can operate a wide range of embodiments and transfer, in a zero- or few-shot manner, to novel robots.
We introduce RING, a generalist policy for indoor visual navigation that learns from a broad spectrum of embodiments, trained exclusively in simulation, without any direct use of actual robot embodiments.
Embodiment Randomization at Scale
We augment the AI2-THOR simulator with the ability to instantiate robot embodiments with controllable configurations, varying across body size, rotation pivot point, and camera configurations.
We model the body of the agent as an invisible collider box in the AI2-THOR simulator. Each agent can have 1 or 2 RGB cameras placed at a random pose within the collider box.
Parameters corresponding to both the body and the cameras are sampled randomly from specified ranges.
We also modify the planner of generating expert trajectories to account for the diversity of embodiments.
Below, we show example trajectories from random embodiments in the AI2-THOR simulator.
Right column shows the egocentric view from the main camera and the left column shows a third-person view of the agent --white boxes indicate the robot colliders for visualization purposes only.
Different embodiments show different behaviors.
Below we show 2 examples of the same trajectory with different embodiments.
For each example, the left frame shows the egocentric view from the main camera and the second one a third-person view of the agent.
Embodiment A, on the left, has a bigger body size compared to Embodiment B (on the right). As a result, B can go under the table to get to the chair but A collides with the table and has to go around.
Training Paradigm and Architecture
We first pretrain our policy on expert trajectories collected from randomized embodiments, followed
by finetuning with on-policy RL, using the randomized embodiments in the AI2-THOR simulator.
RL finetuning is specifically important for the policy to learn to navigate a diverse set of embodiments through trial-and-error.
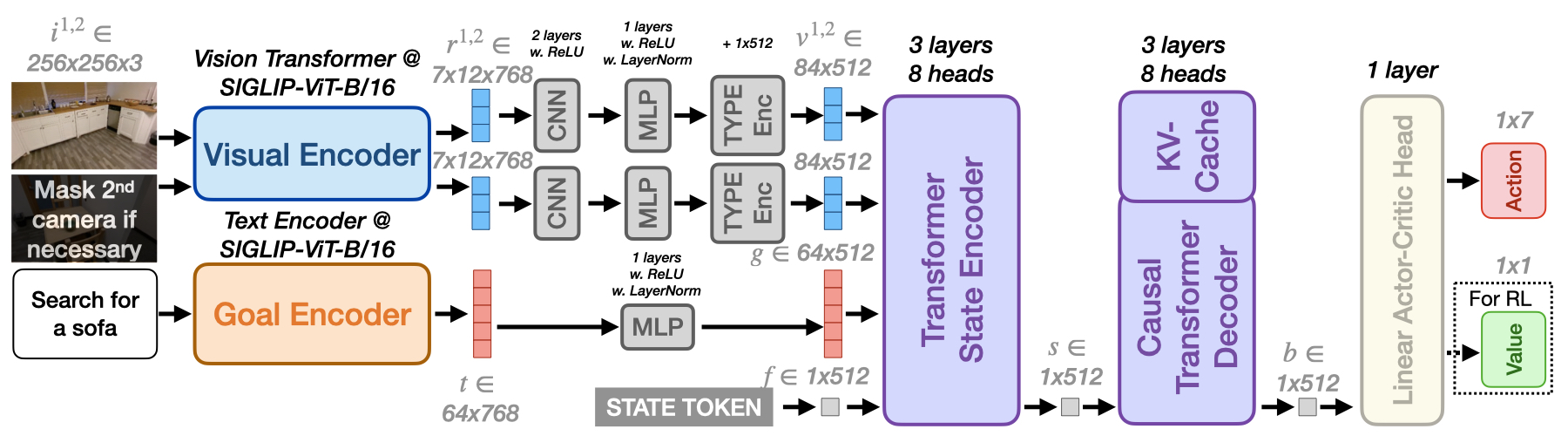
Architecture is outlined in the figure below.
RING Architecture.
RING accepts visual observations and a language instruction as inputs and predicts an action to execute.
During RL finetuning, RING also predicts a value estimate. We mask the image from the $2^{nd}$ camera with all $0$ for the embodiments with only one camera, such as LoCoBot and Unitree Go1. More specifically, we use the Vision Transformer and the Text Encoder from SIGLIP-ViT-B/16 as our visual encoder and goal encoder. After encoding, we compress and project the visual representation $r$ and text embedding $t$ to $v$ and $g$, respectively, with the desired dimension $d=512$. Next, the Transformer State Encoder encodes $v$, $g$, along with STATE token embedding $f$ into a state feature vector $s$. The Causal Transformer Decoder further processes $s$, along with previous experiences stored in the KV-Cache, to produce the state belief $b$. Finally, the Linear Actor-Critic Head predicts action logits (and, during RL finetuning, a value estimate) from $b$.
Quantitative Results
Our experiments show that RING operates effectively across a wide range of embodiments, including actual robots (Stretch RE-1, LoCoBot , and Unitree Go1) and human evaluation with Navigation Assistants, despite being trained exclusively in simulation without any direct exposure to real robot embodiments.
In Simulation
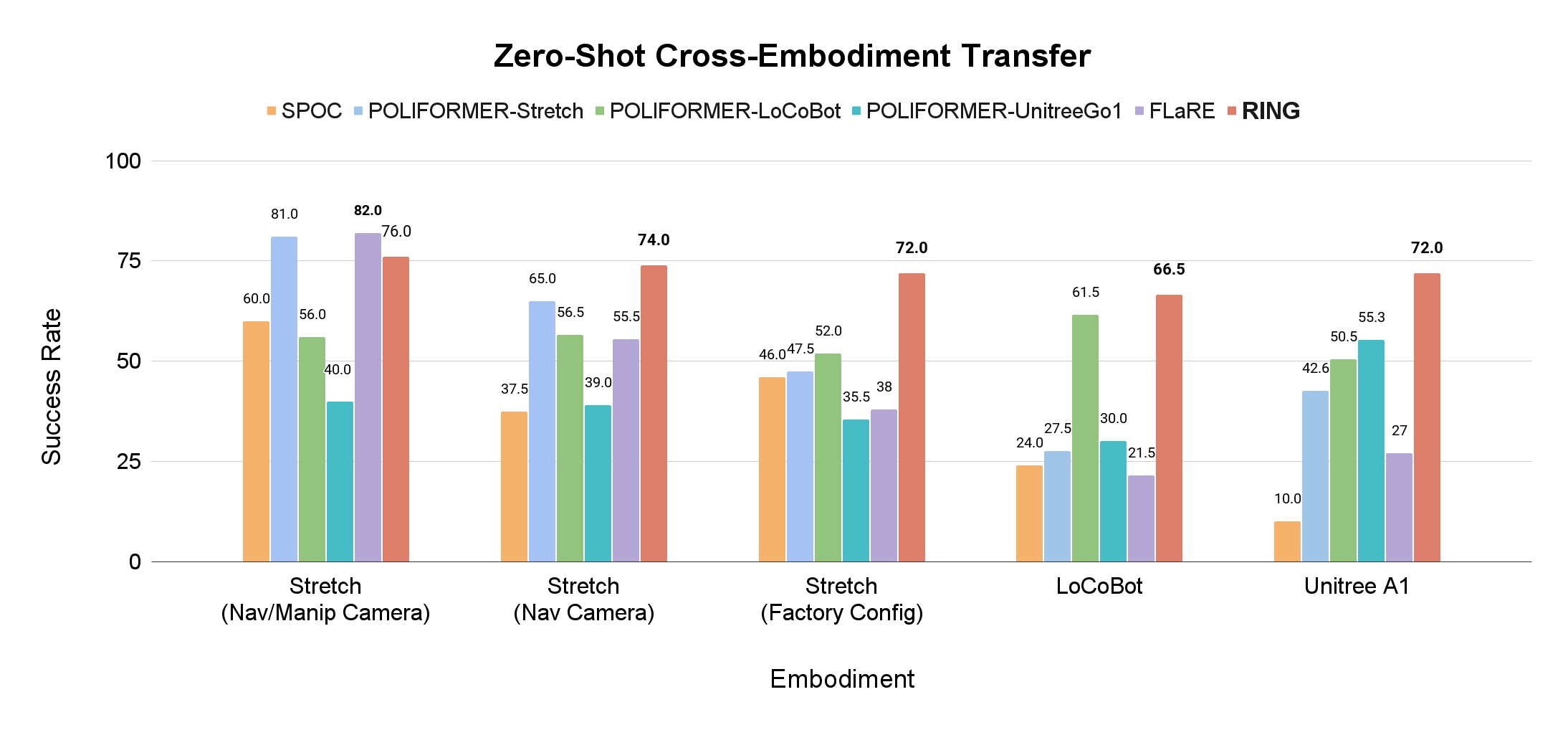
We perform zero-shot evaluate of all policies on four robot embodiments: Stretch RE-1 (with 1 or 2 cameras), LoCoBot, and Unitree A1 in simulation.
RING shows strong generalization across all embodiments despite not being trained on any of them, achieving an average absolute improvement of 16.7% in Success Rate.
In the Real World
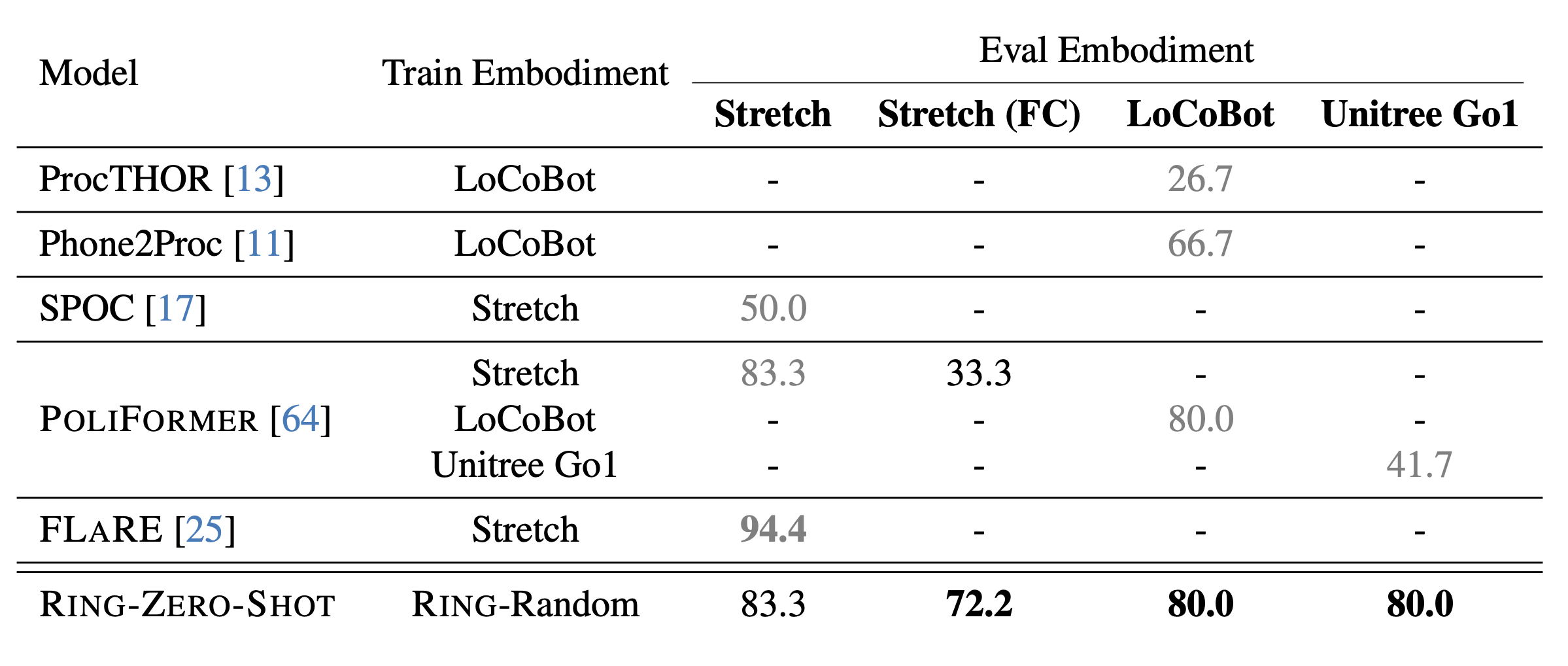
RING transfers zero-shot to the real-world without any finetuning. Gray numbers are evaluated on same embodiment as their training.
RING shows consistent performance across all embodiments achieving 78.9% success rate on average across $4$ real-world robots.
Human Evaluation
We asked 5 participants to navigate in a real-world kitchen area, following the policy’s output actions on their phones.
Each individual has unique characteristics, including step size, height, rotation angles, and camera-holding posture.
Each person navigates to three different objects (Mug, Apple, Houseplant), resulting in a total of $15$ trajectories.
RING shows much better generalization to human embodiment than the FLaRe baseline trained on Stretch RE-1.